
Uno degli aspetti che comunemente non sono così noti e chiari è il fatto che il metodo Kanban aiuta a ridurre il rischio operativo e gli errori previsionali. La difficoltà iniziale delle persone alle quali ne parlo parte proprio dalla comprensione del concetto di rischio operativo. “Quale rischio operativo?” mi chiedono. “Il rischio legato al fatto che a causa di diversi eventi, interni o esterni all’organizzazione, potremmo metterci più di quanto previsto per fare il lavoro” rispondo. “In che senso?” insistono. Allora comincio a porre loro alcune domande.
Il concetto di Lead Time
Chiedo di farmi un esempio di qualche tipica richiesta di lavoro che ricevono. “Quanto tempo ci mettete per evadere questa richiesta di lavoro?” chiedo. La risposta tipicamente è un numero. “Siamo sicuri?” chiedo. “Come varia questo valore a seconda delle circostanze, lo sapete?”. Normalmente la risposta è vaga.
Allora comincio a disegnare su un foglio o su una lavagna una rappresentazione di una semplice Kanban board come in Figura 1. Spiego che chiameremo Lead Time il tempo che ogni richiesta di lavoro (che chiameremo Work Item) ci mette per essere evasa e spiego che il Lead Time non è un unico valore ma una distribuzione di valori. Poi ripeto la domanda: “Quanto tempo ci mettete per evadere questa richiesta di lavoro?” e quindi, senza aspettare la risposta, spiego che il tempo rilevato di evasione della richiesta può variare e comincio ad annotare i valori su un grafico come in Figura 1.
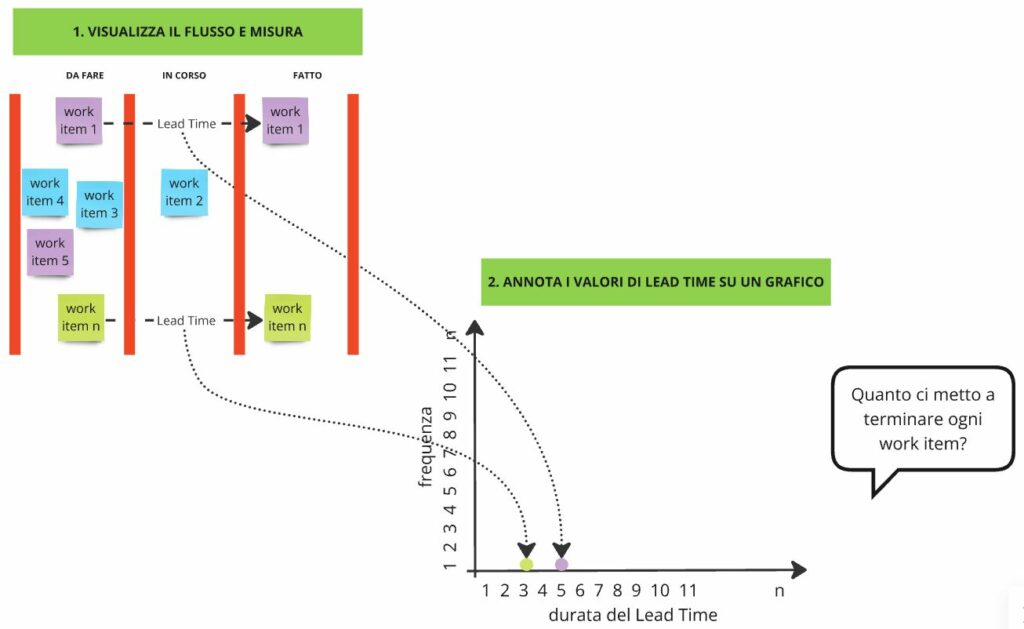
La distribuzione dei Lead Time
Proseguendo ad aggiungere valori chiedo: “succede che i valori di Lead Time si ripetano, giusto?” e così facendo vado ad aggiungere al grafico i valori che si ripetono impilandoli ai precedenti, fino a raggiungere una rappresentazione come in Figura 2. A questo punto verifico con i miei interlocutori se si ritrovano nel grafico disegnato, normalmente rispondono di sì.
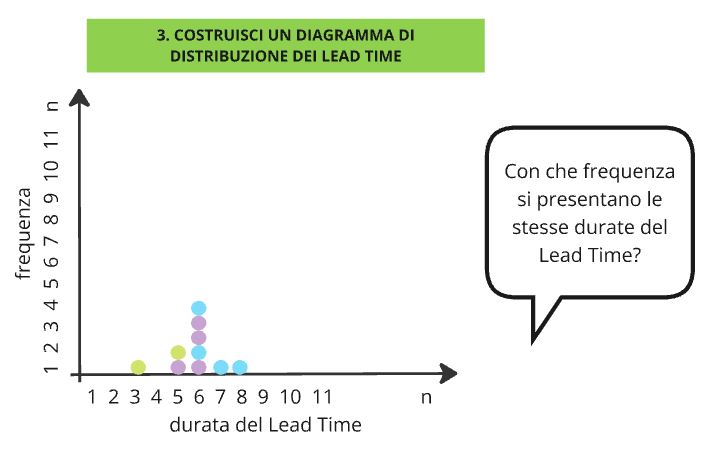
Quale valore utilizzare per fare previsioni
Siamo pronti allora per il passo successivo che consiste nell’invitare i miei interlocutori a rispondere alla domanda: “quale dei valori misurati secondo voi ha senso utilizzare per fare previsioni future?” e qui inizia la vera riflessione, come in Figura 3.
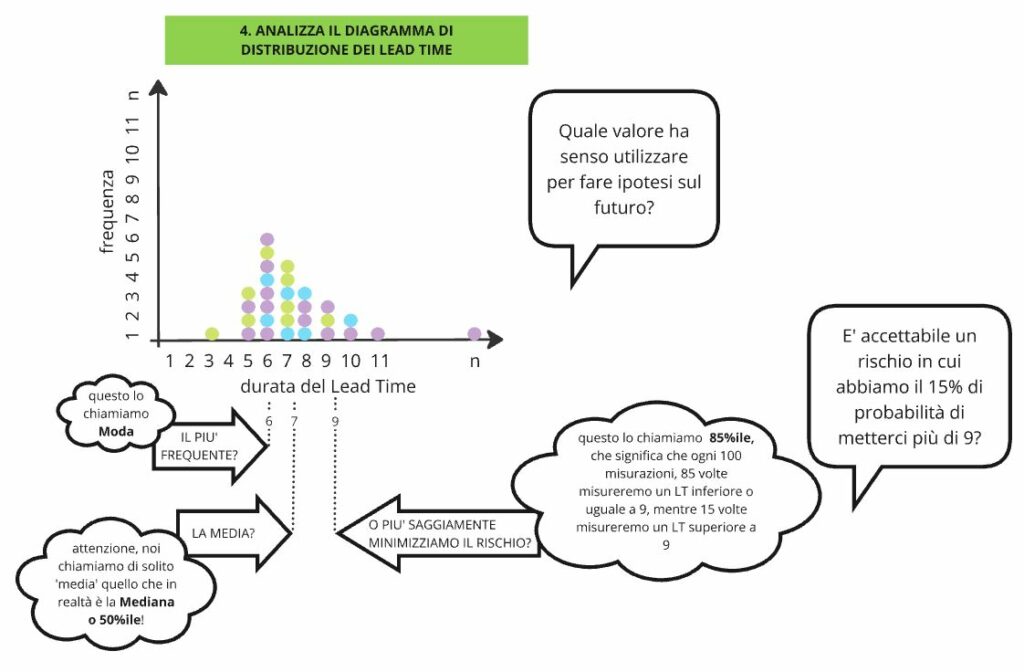
Qualcuno risponde “la media” e allora faccio riflettere sul fatto che solitamente si dice ‘media’ riferendosi a quel valore per cui una volta su due ci si mette di più, mentre una volta su due ci si mette di meno del valore stesso. Questo in termini statistici però non è il concetto di media, ma più propriamente è quello di mediana, anche nota come cinquantesimo percentile. Quindi faccio notare come prendendo a riferimento la mediana saremo in ritardo una volta su due, ossia avremo il 50% di probabilità di non essere puntuali, che è un rischio piuttosto elevato, probabilmente non accettabile.
Qualcuno allora mi risponde “il valore più frequente”. Faccio notare che il valore più frequente, in termini statistici detto moda, nel grafico è tipicamente più a sinistra della mediana, il che significa che ho ancora più probabilità di essere in ritardo rispetto ad utilizzare la mediana, corro un rischio ancora più elevato, superiore al 50%.
Parliamo di rischio operativo
Arrivati a questo punto cambio prospettiva alla riflessione e chiedo “guardiamola dal punto di vista del rischio, quale probabilità di arrivare in ritardo siete disposti ad accettare? O meglio, quale probabilità di arrivare in ritardo sono disposti ad accettare i clienti del vostro servizio?” Qui le risposte sono ovviamente molto diverse a seconda dei servizi e dei casi, ma di base propongo loro di ragionare intorno all’ottantacinquesimo percentile, ovvero il valore previsionale in base al quale ci si prende un rischio del 15% di arrivare in ritardo, che normalmente per i servizi è accettato e che si usa in Kanban.
Per concludere faccio infine notare come fare previsioni sul completamento di una richiesta di lavoro senza misurare i Lead Time e senza effettuare un’analisi statistica sia fuorviante perché essendo noi tutti soggetti ai bias cognitivi e in particolare all’euristica della disponibilità, tenderemo automaticamente ad adottare il valore più frequente, prendendoci dei rischi inaccettabili senza nemmeno rendercene conto.
Conclusione
Chiaramente questo è solo l’inizio e ci sono altri passaggi da fare per introdurre efficacemente gli strumenti statistici, a cominciare dalla comprensione del tipo di curva di distribuzione presente e dalla validazione del modello che emerge dalla rilevazione dei dati. Normalmente però queste riflessioni avviano un percorso evolutivo che porta progressivamente nel tempo a un miglioramento sostanziale dei modelli previsionali, alla stabilizzazione dei flussi di lavoro e quindi a una migliore gestione del servizio.