Gestite i servizi professionali della vostra organizzazione e vi chiedete come affrontare le incertezze del lavoro quotidiano? Vi tovate spesso a fare previsioni che poi si rivelano inesatte, mettendo a rischio la puntualità e la soddisfazione dei clienti?
Partecipate al webinar gratuito in collaborazione con Kanban University e Kanban+ e scoprirete come il metodo Kanban può trasformare radicalmente il modo in cui gestite i vostri servizi, riducendo il rischio operativo e gli errori previsionali, e migliorando significativamente la prevedibilità e la qualità.
Il problema che affrontiamo insieme: molte organizzazioni si trovano di fronte a un rischio operativo, ovvero la possibilità che il lavoro richieda più tempo del previsto a causa di eventi interni o esterni. Spesso, quando ci viene chiesto quanto tempo ci vuole per evadere una richiesta, la risposta fornita è un numero singolo, vago, senza considerare la variabilità delle circostanze. Questo porta a previsioni poco affidabili e a un’elevata probabilità di ritardo.
Perché le vostre previsioni attuali potrebbero non funzionare: durante il webinar, esploreremo perché affidarsi a concetti come la media (più propriamente la mediana o cinquantesimo percentile) o il valore più frequente (moda) per fare previsioni è rischioso. Utilizzando la mediana, avreste il 50% di probabilità di essere in ritardo, e utilizzando invece la moda, questa probabilità sarebbe ancora più alta! Questo accade perché siamo tutti soggetti a bias cognitivi, come l’euristica della disponibilità, che ci porta ad adottare il valore più frequente senza renderci conto dei rischi inaccettabili che stiamo correndo.
La soluzione di Kanban: gestione del rischio e prevedibilità basata sui dati. Il webinar introdurrà al concetto di Lead Time, ovvero il tempo che ogni richiesta di lavoro (chiamata Work Item) impiega per essere completata. Scopriremo che il Lead Time non è un valore unico, ma una distribuzione di valori.
Vi guideremo attraverso:
Come misurare e visualizzare i Lead Time per ottenere una comprensione reale della variabilità del tuo lavoro.
Come utilizzare l’ottantacinquesimo percentile come valore previsionale, accettando un rischio di ritardo molto più contenuto (normalmente il 15%). Questo valore è comunemente adottato per i servizi, ma può essere diverso in funzione del rischio accettabile per il servizio.
L’importanza di limitare il lavoro in corso (WIP), una pratica fondamentale di Kanban che riduce il sovraccarico e migliora la prevedibilità dei tempi di consegna, facendo emergere i colli di bottiglia e aumentando l’efficienza del flusso.
Come il metodo Kanban, oltre a gestire il rischio operativo, è un approccio evolutivo e sostenibile che facilita l’adozione di pratiche che migliorano continuamente i modelli previsionali, stabilizzano i flussi di lavoro e portano a una migliore gestione del servizio.
Kanban: non solo per l’IT, ma per tutti i servizi professionali. Sebbene Kanban sia spesso associato al settore IT e si integri perfettamente con popolari framework di settore, ad esempio ITIL, la sua applicazione è universale. Kanban aiuta a gestire efficacemente le operazioni quotidiane (Enterprise Services Management) e funge da catalizzatore per la trasformazione e l’evoluzione strategica delle organizzazioni (Enterprise Services Transformation). La sua forza sta nel promuovere un cambiamento incrementale, senza imporre stravolgimenti drastici, ma lavorando con ciò che già esiste per far evolvere le pratiche organizzative.
A chi è rivolto questo webinar? Questo webinar è pensato per persone che vogliono rendere la loro attività più efficace, con servizi prevedibili e di alta qualità. Kanban è il punto di partenza ideale.
Cosa imparerete? Acquisirete una comprensione iniziale di come:
Migliorare la vostra capacità di fare previsioni accurate.
Gestire in modo più efficace il vostro flusso di lavoro.
Prendere decisioni basate su dati reali, non su intuizioni soggettive.
Non perdete l’opportunità di migliorare la prevedibilità e la qualità dei vostri servizi professionali!
Nel panorama economico odierno, caratterizzato da rapidi mutamenti tecnologici, economici e sociali, le organizzazioni di servizi si trovano spesso a navigare in acque turbolente. L’abilità di evolvere positivamente, mantenendo la stabilità e la pertinenza, è diventata un imperativo per la continuità operativa a lungo termine. Il metodo Kanban, supportato dal Kanban Maturity Model (KMM), offre ai dirigenti aziendali una guida pragmatica per affrontare queste sfide, fondando il proprio approccio su tre agende interconnesse: la sostenibilità, l’orientamento al servizio e l’adattabilità.
Comprendere il contesto turbolento
I periodi di equilibrio organizzativo possono essere interrotti da eventi drammatici che, pur potendo essere preceduti da turbolenze, sono seguiti da caos e ulteriore instabilità, fino al raggiungimento di una “nuova normalità”. Una situazione di tensione può esistere anche in periodi di apparente stabilità, dove problemi latenti (spesso manifestati come inerzia o insoddisfazione) possono portare a una crisi significativa, come durante la crisi finanziaria del 2008.
In questi contesti, la resistenza umana al cambiamento è un fattore critico. Come osservato da Peter Senge, “le persone non resistono al cambiamento, resistono all’essere cambiate”. I cambiamenti drastici e strutturali sul posto di lavoro (nuovi ruoli, riorganizzazioni) possano generare ansia, stress e paura, portando a una forte opposizione. Gli approcci tradizionali, spesso aggressivi e focalizzati su cambiamenti radicali, possono mettere le persone in una situazione di crisi psicologica, mettendo in seria difficoltà anche le organizzazioni.
Il metodo Kanban, al contrario, adotta un approccio al cambiamento evolutivo e incrementale, che evita di provocare una crisi nelle persone. Questo lo rende particolarmente adatto per guidare le organizzazioni attraverso la turbolenza, minimizzando gli effetti dannosi e il turnover del personale.
Le tre agende di Kanban: una bussola per la leadership
Le tre agende di Kanban forniscono una struttura integrata per la crescita e la resilienza aziendale:
L’agenda della sostenibilità: rivolta verso l’interno dell’organizzazione, questa agenda si concentra su tre obiettivi fondamentali, alleviare il sovraccarico di lavoro, migliorare la qualità dei risultati e sviluppare un autentico coinvolgimento professionale, sia nel contributo individuale che nella soddisfazione del cliente. Nei contesti meno strutturati, l’enfasi iniziale è posta sul sollievo dal sovraccarico per persone, team e flussi di lavoro, creando le condizioni per una maggiore qualità e prevedibilità del lavoro svolto. Il risultato è un ambiente professionale più sano, sostenibile e produttivo — condizione indispensabile per affrontare con efficacia le pressioni e le complessità esterne.
L’agenda dell’orientamento al servizio: rivolta verso l’esterno, questa agenda si concentra sulla prestazione del servizio e sulla soddisfazione del cliente, promuovendo la capacità di mantenere gli impegni, rispettare le scadenze con affidabilità e prendere decisioni gestionali basate sulla fiducia reciproca. Nel Kanban Maturity Model (KMM), il ruolo del cliente viene reso esplicito a partire dal livello 2, mentre il livello 3 rappresenta il punto in cui le aspettative del cliente sono soddisfatte in modo costante e sostenibile. Questa agenda orienta l’organizzazione verso il valore percepito dal cliente, stimolando un miglioramento della prevedibilità del servizio e della fiducia esterna — due elementi essenziali per competere efficacemente in contesti di mercato instabili e ad alta variabilità.
L’agenda dell’adattabilità: questa agenda ha uno sguardo orientato al futuro e si concentra sullo sviluppo della resilienza organizzativa e della competitività sostenibile. Lo fa attraverso la capacità di fare promesse credibili e mantenibili e di guidare consapevolmente la strategia e il posizionamento dell’impresa nel tempo. È l’agenda che abilita le organizzazioni a diventare anti-fragili: capaci non solo di resistere alle pressioni esterne, ma di evolversi e rafforzarsi proprio in risposta agli stress ambientali. Questa prospettiva si manifesta pienamente solo nei livelli più evoluti di strutturazione organizzativa, dove diventa possibile una reinvenzione profonda dell’identità e dello scopo aziendale.
Come le agende supportano i dirigenti nell’evoluzione
L’integrazione di queste tre agende, guidata dal KMM, offre ai dirigenti e ai decisori aziendali una strategia robusta per l’evoluzione organizzativa in contesti turbolenti:
Cambiamento evolutivo, non radicale: fin dalla sua origine, il metodo Kanban adotta un approccio incrementale e adattivo al miglioramento dell’agilità organizzativa, in netto contrasto con i cambiamenti drastici e imposti tipici di altre metodologie. Questa via evolutiva, più rispettosa delle dinamiche umane, evita traumi organizzativi e resistenze psicologiche, rendendo il cambiamento più sostenibile e più facile da radicare nel tempo. In particolare, nelle organizzazioni meno strutturate, un approccio graduale e contestuale aumenta significativamente le probabilità di successo, rispetto a trasformazioni radicali avviate attraverso grandi iniziative di transizione.
Prevenzione delle crisi: anziché aspettare una crisi conclamata per avviare il cambiamento, Kanban promuove un intervento proattivo durante i periodi di stabilità, quando i problemi latenti possono essere affrontati con maggiore lucidità. Le agende del metodo supportano l’emersione e la risoluzione di insoddisfazioni e ostacoli operativi — come il sovraccarico di lavoro o le inefficienze nel flusso — trasformando l’inerzia organizzativa in spinta al miglioramento.
Costruire resilienza e adattabilità: Il metodo Kanban, attraverso le sue agende, favorisce lo sviluppo di resilienza strategica, operativa e individuale. Questo percorso comprende transizioni culturali e organizzative fondamentali: dalla burocrazia alla dinamicità emergente, dalla formalizzazione alla personalizzazione, dall’efficienza all’affidabilità e dal profitto alla ricerca di significato. Il modello contribuisce a sviluppare una maggiore sensibilità al contesto esterno e una tolleranza costruttiva verso nuove idee — tratti distintivi delle organizzazioni davvero resilienti. Nei contesti più strutturati, il KMM abilita la capacità di mettere in discussione in modo critico il come, il cosa, il perché e il per chi si lavora, una competenza chiave per la reinvenzione continua e la sopravvivenza nel lungo termine.
Decisioni basate sui dati e sul feedback continuo: le agende incoraggiano un uso sistematico di metriche e cicli di feedback, attraverso le cosiddette ‘Cadenze Kanban’ — come il Kanban Meeting, il Service Delivery Review e l’Operations Review. Questi momenti strutturati abilitano un’auto-valutazione onesta e una comprensione quantitativa della performance, fornendo ai decisori le informazioni necessarie per prendere decisioni consapevoli e adattarsi con rapidità ai cambiamenti del contesto.
Promuovere la leadership a ogni livello: Kanban promuove la leadership diffusa, incoraggiando atti di leadership a tutti i livelli dell’organizzazione — dalla proattività individuale alla capacità di mobilitare e ispirare il gruppo. Questo approccio distribuisce responsabilità e potere decisionale, rendendo l’organizzazione più resiliente, adattabile e meno dipendente da singole figure carismatiche o ‘manager eroi’.
Cambiamento duraturo: Kanban è progettato per garantire che il cambiamento culturale e l’adozione di nuove pratiche si consolidino e perdurino nel tempo, anche in presenza di turnover del personale. Le agende, i valori espliciti e i criteri decisionali fungono da guida, supportando un’evoluzione profonda e sostenibile che si radica saldamente nella cultura organizzativa.
Conclusione
In conclusione, le tre agende di Kanban – sostenibilità, orientamento al servizio e adattabilità – non sono solo principi teorici, ma una guida pratica per i dirigenti che desiderano condurre le loro organizzazioni di servizi verso un’evoluzione positiva in un ambiente sempre più turbolento. Adottando questo approccio sistemico e allo stesso tempo umano al cambiamento, le organizzazioni possono non solo resistere agli shock, ma anche emergere più forti, più agili e con una maggiore probabilità di successo a lungo termine.
Uno degli aspetti che trovo più affascinanti e rivoluzionari di Kanban è l’abolizione della pianificazione nel senso tradizionale del termine. Un’affermazione che, in ambito aziendale, spesso suscita sguardi perplessi e il sospetto che si tratti di una mera provocazione. Eppure, il punto è proprio questo: Kanban elimina la pianificazione perché essa, semplicemente, non funziona. Il motivo? L’impossibilità di prevedere ogni variabile in modo deterministico.
Al suo posto, Kanban introduce un approccio diverso, basato sull’analisi del rischio e dell’incertezza. Più che pianificare, si adotta un approccio di forecasting che è sorprendentemente vicino a quello della “navigazione stimata” nella barca a vela. Proprio come un’imbarcazione che si muove sulla superficie al confine tra due fluidi e adatta la sua rotta alle condizioni del vento e del mare, un sistema Kanban si muove in un contesto dinamico e complesso, dove la realtà non segue schemi prestabiliti. E forse è proprio questa la sua forza: accettare l’incertezza, invece di combatterla con previsioni che spesso si rivelano illusorie, e imparare a navigarla con agilità.
La navigazione stimata
La navigazione stimata in barca a vela è un metodo per determinare la propria posizione e tracciare la rotta basandosi su calcoli e osservazioni di punti di riferimento, venti, correnti e condizioni meteorologiche. Si parte da un punto noto e, tenendo conto della velocità dell’imbarcazione, della direzione del vento, della corrente e del tempo trascorso, si stima dove ci si trova in un dato momento. Questo approccio non è statico, ma dinamico: man mano che si procede, si raccolgono nuove informazioni – ad esempio, cambiamenti nelle condizioni meteo o nella direzione e intensità del vento – e si adatta la rotta e la previsione di viaggio di conseguenza. Proprio come in un sistema Kanban, la chiave della navigazione stimata non è pianificare rigidamente, ma correggere il percorso in base alla realtà del momento, accettando l’incertezza come parte integrante del viaggio.
Parallelismi tra la navigazione stimata e Kanban
Dipendenza dalle condizioni attuali
Sia in mare che nei progetti, le condizioni iniziali sono solo un punto di partenza. Un navigatore si basa su venti, correnti e posizione attuale per prendere decisioni consapevoli e adattare continuamente la rotta. Allo stesso modo, un team Kanban osserva il flusso di lavoro, identifica i colli di bottiglia, e modifica le modalità di gestione del flusso di lavoro in base a ciò che emerge. L’attenzione si concentra su ciò che è “in corso”, limitando il carico di lavoro per garantire che ogni attività sia completata prima di iniziarne un’altra.
Previsioni e non certezze
Un navigatore può prevedere la durata del viaggio, ma sa che condizioni non del tutto previste possono influenzare il percorso e utilizza in modo costante le previsioni meteomarine, che sono basate su analisi di tipo probabilistico. Similmente, in Kanban si utilizzano misure basate su dati storici per prevedere la durata delle attività, tenendo però sempre conto della loro variabilità statistica per fare un’analisi di probabilità.
Adattamento continuo alle condizioni
Il viaggio di una barca a vela non è mai lineare. I navigatori correggono costantemente la rotta, sfruttando le nuove informazioni e reagendo agli imprevisti. Anche in Kanban, la gestione del flusso è un processo iterativo, dove si acquisiscono informazioni e si incontrano ostacoli imprevisti lungo il percorso e si adatta il modo di lavorare di conseguenza.
Monitoraggio continuo
Il navigatore utilizza gli strumenti di bordo e i rilevamenti per verificare la posizione e confrontarla con il percorso pianificato. In Kanban le metriche come il lead time e il throughput aiutano a capire se il sistema sta funzionando correttamente e dove sono necessari interventi.
Importanza della comunicazione
Una buona comunicazione è vitale sia a bordo di una barca a vela che in un team Kanban. I membri dell’equipaggio devono condividere informazioni sulle condizioni del mare e sulle manovre necessarie. Analogamente, la trasparenza e la collaborazione sono essenziali in Kanban per garantire che tutti i membri del team siano allineati e informati.
Flessibilità e feedback
La navigazione stimata privilegia l’adattamento alle circostanze rispetto a un piano rigido, un navigatore pone costante attenzione ai segnali ambientali e sviluppa la capacità di anticipare i cambiamenti. In Kanban allo stesso modo, i cicli di feedback costanti e la flessibilità sono fondamentali per reagire tempestivamente ai cambiamenti e garantire il successo dei progetti e dei servizi.
Gestione delle dipendenze
Come un navigatore deve considerare le maree e le correnti, un team Kanban deve gestire le dipendenze tra le attività. Questo richiede accorgimenti e meccanismi opportuni per garantire che il flusso di lavoro non venga interrotto.
Orientamento al flusso
In barca a vela, uno degli obiettivi fondamentali è mantenere l’imbarcazione in movimento, adattandosi continuamente alle condizioni del vento e del mare. Il navigatore controlla costantemente il movimento della barca, regolando le vele per mantenere la rotta. Se la barca si ferma o perde troppo slancio, ripartire diventa difficile e inefficiente. Lo stesso principio si applica al concetto di flusso in Kanban, l’obiettivo è mantenere il flusso costante, garantendo che il lavoro proceda senza intoppi, riducendo blocchi e interruzioni.
Non conta partire, conta arrivare
In barca a vela, ciò che conta davvero non è la velocità assoluta dell’imbarcazione, ma la Velocity Made Good (VMG) on course, ovvero la velocità effettiva con cui ci si sta avvicinando alla destinazione. Una barca può muoversi rapidamente, ma se la direzione non è quella giusta, il progresso reale sarà minimo. Lo stesso principio si applica a Kanban, non è importante quanto velocemente si lavora in un dato momento, ma quanto lavoro viene effettivamente consegnato. L’obiettivo non è essere sempre impegnati o lavorare al massimo della velocità, ma completare il lavoro nel modo più efficiente possibile, riducendo sprechi e rallentamenti. Come in navigazione, l’essenziale non è l’illusione del movimento, ma il progresso reale verso la meta.
Conclusione
Kanban e la navigazione stimata in barca a vela condividono un principio fondamentale: il successo non dipende da piani rigidi, ma dalla capacità di osservare, misurare, adattarsi e rispondere ai cambiamenti. In entrambi i casi, l’obiettivo non è fissare una rotta immutabile, ma ottimizzare il flusso per avanzare in modo efficiente e consapevole. Così come un velista parte con una direzione generale, sfrutta previsioni e stime per tracciare il percorso, ma è sempre pronto a correggere la rotta in base alle condizioni reali, allo stesso modo Kanban permette di gestire il lavoro in modo dinamico, adattandosi alle sfide man mano che emergono. Questa flessibilità non è solo una necessità, ma la chiave per navigare con successo la complessità, trasformando ogni progetto o servizio in un viaggio in cui conta non solo la meta, ma anche il modo in cui la si raggiunge.
Le normative europee DORA (Digital Operational Resilience Act) e NIS2 (Network and Information Security Directive 2) pongono nuove sfide alle aziende, imponendo requisiti più stringenti e cogenti in termini di resilienza digitale e sicurezza informatica. Entrambe mirano a garantire la continuità operativa e la gestione efficace del rischio ICT, seppur con ambiti differenti: DORA si concentra sul settore finanziario, mentre NIS2 si applica a un’ampia gamma di settori critici.
In questo contesto, il metodo Kanban offre strumenti concreti per migliorare la gestione del rischio, ottimizzare i processi e garantire la conformità normativa attraverso un monitoraggio costante e l’uso di metriche chiave.
DALL-E AI generated image
Kanban e la resilienza digitale nel contesto di DORA e NIS2
Nello specifico il metodo Kanban, con il suo approccio evolutivo, aiuta le organizzazioni a:
Migliorare la prevedibilità e il controllo del flusso di lavoro, garantendo un’operatività stabile e resiliente.
Ottimizzare la gestione degli incidenti e delle vulnerabilità informatiche, rispettando i tempi di notifica e risoluzione imposti da DORA e NIS2.
Monitorare le performance e l’efficacia delle misure di sicurezza, grazie a metriche chiare e aggiornate in tempo reale.
Metriche Kanban per la conformità a DORA e NIS2
Le metriche Kanban permettono di valutare e migliorare la resilienza operativa e la gestione del rischio ICT. Le principali metriche applicabili sono:
1. Lead Time e Cycle Time
Lead Time misura il tempo necessario per completare un’attività dall’inizio alla fine, utile per monitorare la velocità di risposta agli incidenti e garantire il rispetto delle tempistiche di notifica imposte da DORA e NIS2.
Cycle Time si concentra sul tempo impiegato per completare specifiche fasi di un processo, aiutando a migliorare la gestione delle vulnerabilità e l’implementazione di misure di sicurezza.
2. Throughput
Indica il numero di attività completate in un determinato periodo. Nel contesto normativo, aiuta a monitorare la capacità di risposta agli incidenti, il numero di test di sicurezza eseguiti e le misure di mitigazione adottate.
3. Work in Progress (WIP)
Limitare il WIP previene il sovraccarico dei team, garantendo che le risorse siano allocate in modo efficiente e che le attività più critiche vengano gestite con priorità.
4. Cumulative Flow Diagram (CFD)
Fornisce una visione chiara del flusso di lavoro, aiutando a identificare colli di bottiglia e ritardi nella gestione della sicurezza informatica e della resilienza operativa.
5. Blockers
Evidenziano ostacoli che rallentano o bloccano il flusso di lavoro, come ritardi nelle decisioni di sicurezza o problemi nella gestione delle terze parti, aspetti fondamentali per DORA e NIS2.
6. Lead Time di recupero
Misura il tempo necessario per ripristinare completamente un sistema dopo un incidente, in linea con i requisiti di continuità operativa previsti da entrambe le normative.
Kanban e il rispetto degli SLA
Gli SLA (Service Level Agreements) definiscono i livelli di servizio garantiti, tra cui tempi di risposta, ripristino e mitigazione delle minacce. Grazie alle metriche Kanban, le aziende possono:
Monitorare in modo continuo il rispetto degli SLA relativi alla sicurezza e resilienza operativa.
Individuare inefficienze nei processi e ottimizzare la gestione delle risorse.
Garantire una risposta più rapida agli incidenti, riducendo i tempi di inattività e i rischi operativi.
I benefici di un flusso di lavoro stabile e prevedibile
Oltre alla conformità normativa, un flusso di lavoro ottimizzato con Kanban porta numerosi vantaggi:
Soddisfazione del cliente: una maggiore affidabilità nei servizi rafforza la fiducia e la reputazione aziendale.
Agilità aziendale: una gestione più flessibile e reattiva facilita l’adattamento ai cambiamenti normativi e tecnologici.
Cultura del miglioramento continuo: team più consapevoli e proattivi nel migliorare i processi di sicurezza e resilienza.
Minore sovraccarico del personale: un carico di lavoro bilanciato riduce lo stress, migliorando il benessere e la produttività.
Migliore trasparenza: una chiara visione dello stato del lavoro facilita la collaborazione tra team e stakeholder.
Migliore pianificazione e previsione: maggiore accuratezza nel rispetto delle scadenze e delle normative.
Conclusione
L’adozione del metodo Kanban nell’implementazione di DORA e NIS2 rappresenta un’opportunità strategica per migliorare la resilienza digitale e la sicurezza informatica. Grazie a un monitoraggio efficace e a metriche specifiche, le aziende possono:
Rafforzare la protezione contro le minacce cyber.
Migliorare la gestione degli incidenti e delle vulnerabilità.
Ottimizzare le risorse e garantire la continuità operativa.
Assicurare la conformità normativa e il rispetto degli SLA.
L’integrazione di Kanban nei processi aziendali consente di trasformare la sicurezza informatica e la resilienza operativa in un vantaggio competitivo, rendendo le organizzazioni più sicure, efficienti e reattive alle sfide del futuro.
David J. Anderson, Kanban: Successful Evolutionary Change for Your Technology Business, Blue Hole Press, 2010
David J. Anderson, Teodora Bozheva, Kanban Maturity Model: A Map to Organizational Agility, Resilience, and Reinvention – 2nd Edition, Kanban University Press, 2021
ISO/IEC 27001:2022 – Information Security Management Systems
ENISA – Guidelines on Cybersecurity Measures under NIS2
Un breve articolo che ho letto in questi giorni mi ha ricordato una grande verità: nessuno si ricorderà o renderà merito agli eroi silenziosi che giorno per giorno, con piccoli costanti cambiamenti, permettono alle organizzazioni di prosperare prevenendo i problemi ed evitando i rischi.
Così come tutti si ricordano i pompieri che hanno spento un incendio e salvato vite ma nessuno si ricorda di chi altrove, con un lavoro nascosto e costante di prevenzione, ne ha evitati magari a decine con un impatto reale molto maggiore.
Ne avevo già parlato a proposito del ruolo di project manager in un precedente post che potete rileggere qui, ma vale per qualunque ruolo aziendale. Non servono eroi, servono risk manager.
Riporto l’articolo originale di Dimitar Bakardzhiev (la traduzione è mia):
“Avete mai notato che gli ingranaggi organizzativi di solito girano senza alcun plauso per le menti che li guidano?
Ciò evidenzia la realtà del management: gli stessi individui o le iniziative che guidano la trasformazione sono spesso trascurati o sottovalutati.
Questi eroi non celebrati – manager che risolvono silenziosamente i conflitti, implementano sistemi che prevengono il caos o motivano i team a superare le aspettative – raramente fanno notizia.
Eppure, sono le ancore che tengono a galla e fanno prosperare le organizzazioni. Il loro contributo, anche se impercettibile, è la spina dorsale del progresso.
Forse è giunto il momento di fermarsi e chiedersi: stiamo davvero riconoscendo i catalizzatori nelle nostre organizzazioni o lasciamo che il successo metta in ombra i suoi architetti silenziosi?
Iniziamo a celebrare non solo i risultati, ma anche le menti umili che li rendono possibili.”
Per far funzionare bene un sistema organizzativo e i suoi flussi di lavoro è fondamentale una gestione proattiva dei rischi, che infatti è un filo conduttore chiave del metodo Kanban. In tre degli ultimi cinque articoli ho già trattato il tema del rischio e di come viene affrontato per migliorare le previsioni e rendere i flussi di lavoro più stabili e affidabili. In questo articolo voglio risalire alla fonte e spiegare quali sono i razionali di base di tale approccio.
Le radici concettuali: il pensiero di Taleb, Shewhart e Deming
Nassim Nicholas Taleb, nel suo pensiero sul rischio, esplora il concetto di incertezza e imprevedibilità, evidenziando come molti eventi significativi (i cosiddetti ‘Cigni Neri’) siano estremamente improbabili, ma hanno un impatto enorme e sono spesso razionalizzati solo a posteriori. Taleb critica la dipendenza da modelli statistici tradizionali che sottovalutano le dinamiche dell’incertezza e del caos. Introduce inoltre il concetto di antifragilità, ovvero la capacità di un sistema di non solo resistere agli shock, ma di trarne beneficio e crescere. Taleb incoraggia un approccio prudente e resiliente al rischio, valorizzando la robustezza e il fattore umano rispetto alla fiducia cieca nella previsione e nel controllo.
Mediocristan ed Extremistan
Una delle idee chiave di Taleb, che ha influenzato ed è stata ripresa dal metodo Kanban, è la distinzione tra Mediocristan ed Extremistan per descrivere due tipi di domini statistici che influenzano la nostra comprensione del rischio e dell’incertezza.
Mediocristan:
Caratteristiche: Si riferisce a un mondo in cui le variabili seguono una distribuzione normale o gaussiana. Gli eventi estremi (outlier) sono rari e hanno un impatto minimo sull’insieme. La maggior parte delle variazioni è contenuta entro limiti prevedibili.
Esempi: Peso o altezza di un gruppo di persone. Aggiungere una persona di altezza straordinaria o peso anomalo non cambia significativamente la media complessiva.
Principio: Le dinamiche sono dominabili e i fenomeni sono relativamente stabili.
Extremistan:
Caratteristiche: Si riferisce a un mondo dominato da distribuzioni a coda grassa o lunga (fat-tail), dove eventi estremi sono frequenti e possono avere un impatto sproporzionato. I valori eccezionali contano molto di più rispetto alla media.
Esempi: Ricchezza, successo editoriale, popolarità di un video online. Un singolo miliardario o bestseller può influenzare enormemente la media.
Principio: Le dinamiche sono altamente imprevedibili e dominano le eccezioni.
Mediocristan è il dominio della stabilità, dove gli eventi rari non contano molto, mentre Extremistan è il regno dell’incertezza e degli eventi straordinari, che possono alterare radicalmente la realtà. Secondo Taleb, il mondo reale, soprattutto in ambiti come l’economia o l’innovazione, è spesso più vicino all’Extremistan, rendendo fondamentale considerare i rischi di eventi eccezionali (i ‘Cigni Neri’).
Rischi di variazione per causa comune e rischi di variazione per causa speciale
I rischi nei sistemi Kanban vengono classificati come rischi di variazione per causa comune (chance cause variation) e rischi di variazione per causa speciale (assignable cause variation). Questi concetti derivano dal lavoro pionieristico di Walter Shewhart negli anni ’20 del secolo scorso e sono stati ulteriormente sviluppati da William Edwards Deming, influenzando profondamente il Toyota Production System da cui il metodo Kanban deriva direttamente. La differenza tra questi rischi è un concetto fondamentale per la gestione del flusso di lavoro in un sistema Kanban.
Variazioni per causa comune:
Sono intrinseche al sistema e derivano dalla normale variabilità dei processi di lavoro.
Sono sempre presenti e contribuiscono alla fluttuazione “naturale” delle prestazioni.
Esempi: lievi differenze nei tempi di completamento delle attività, piccole variazioni nella qualità del lavoro, fluttuazioni nella domanda di lavoro.
Gestione: si affrontano migliorando il sistema nel suo complesso, ottimizzando i processi e riducendo la variabilità intrinseca.
Variazioni per causa speciale:
Sono esterne al sistema e derivano da eventi specifici e identificabili.
Sono imprevedibili e causano deviazioni significative dalle prestazioni normali.
Esempi: guasti imprevisti alle apparecchiature, richieste urgenti non pianificate, assenze improvvise del personale, ritardi da parte di fornitori esterni.
Gestione: si affrontano identificando la causa specifica, intervenendo per risolvere il problema immediato e implementando misure preventive per evitare che si ripeta in futuro.
I concetti di Extremistan e Mediocristan, introdotti da Taleb, sono strettamente correlati ai concetti di rischi di variazione per causa comune e rischi di variazione per causa speciale:
I rischi di variazione per causa comune sono tipici del Mediocristan. Sono variazioni intrinseche al sistema, con un impatto limitato e prevedibile. Possono essere gestiti migliorando il sistema nel suo complesso e riducendo la variabilità intrinseca.
I rischi di variazione per causa speciale sono tipici dell’Extremistan. Sono variazioni imprevedibili, spesso causate da eventi esterni al sistema, che possono avere un impatto significativo sulle prestazioni. Richiedono un’azione immediata per identificare e risolvere la causa specifica, oltre a misure preventive per evitare che si ripetano in futuro.
Il ruolo del Lead Time
L’analisi dei tempi di consegna (Lead Time) in un sistema Kanban può rivelare se ci troviamo di fronte a un Mediocristan o a un Extremistan:
Tempi di consegna con una distribuzione ‘a coda sottile’ (thin-tailed) indicano un Mediocristan: la maggior parte dei lead time si concentra attorno alla media, con pochi outlier. Possiamo utilizzare i valori di Lead Time per fare delle previsioni e pianificare.
Tempi di consegna con una distribuzione ‘a coda grassa o lunga’ (fat-tailed) indicano un Extremistan: la media è influenzata da outlier estremi, rendendola un indicatore poco affidabile. Dobbiamo analizzare gli outlier e anticipare i loro effetti con contromisure specifiche (in gergo si parla di “tagliare la coda”).
La pratica Kanban di limitare il WIP (Work in Progress) ha lo scopo di ottenere una distribuzione dei lead time a coda sottile, tipica del Mediocristan. Limitando il lavoro in corso, si riduce la variabilità del sistema, rendendolo più prevedibile e meno soggetto a eventi estremi.
Un percorso evolutivo per imparare a gestire i rischi
Il Kanban Maturity Model (KMM) sottolinea l’importanza di imparare a distinguere tra rischi di variazione per causa comune e rischi di variazione per causa speciale, per una gestione del rischio efficace. Nei livelli di maturità più bassi, le organizzazioni tendono a reagire a tutte le variazioni come se fossero speciali, con un approccio reattivo e spesso inefficace.
Man mano che l’organizzazione matura, sviluppa la capacità di:
Riconoscere le variazioni per causa comune e concentrarsi sul miglioramento continuo del sistema.
Identificare rapidamente le variazioni per causa speciale, intervenire per risolvere i problemi e implementare misure preventive.
Questa capacità di discernimento è cruciale per migliorare il flusso di lavoro, ridurre i rischi e aumentare la prevedibilità delle prestazioni.
Superare la mentalità vittimistica
Un ostacolo al discernimento dei rischi è che in molti ambienti aziendali la presunta complessità del contesto (cioè considerare tutte le variazioni come se fossero per causa speciale, mentre in realtà sono per causa comune) viene usata come scusa per giustificare le proprie prestazioni inadeguate. Le difficoltà esterne sono addotte come unica ragione delle scarse prestazioni, attribuendo i propri insuccessi a fattori esterni anziché a carenze personali o di metodo, di conseguenza evitando di assumersi la responsabilità di migliorare il sistema di lavoro.
Tale mentalità è particolarmente diffusa in ambienti di lavoro con bassa maturità. Si parla di ‘abdicazione’ in relazione alla leadership. Un leader che abdica alle proprie responsabilità, evitando di prendere decisioni e di affrontare i problemi, contribuisce a creare un ambiente in cui si diffonde una mentalità vittimistica. I membri del team, non sentendosi guidati e supportati, tenderanno a scaricare la colpa altrove e a lamentarsi invece di cercare soluzioni.
Al contrario un ambiente di lavoro positivo e collaborativo, con una leadership forte e supportiva, può contribuire a contrastare la mentalità vittimistica. Quando le persone si sentono valorizzate, responsabilizzate e parte di un team, sono più propense ad affrontare le sfide con un atteggiamento positivo e proattivo.
Evolvere la propria gestione del rischio insieme alla maturità organizzativa
La gestione del rischio nel Kanban Maturity Model (KMM) evolve significativamente attraverso i diversi livelli di maturità. Man mano che un’organizzazione matura, la sua capacità di identificare, analizzare e mitigare i rischi diventa più sofisticata e integrata nella sua cultura e nei suoi processi.
Ecco una panoramica di come il rischio viene gestito ai diversi livelli di maturità:
Livello 0 – Oblivious: A questo livello, il rischio non viene gestito in modo consapevole. L’organizzazione non ha processi definiti per l’identificazione o la mitigazione dei rischi, e le decisioni vengono prese in modo reattivo, spesso solo dopo che i problemi si sono già verificati.
Livello 1 – Team Focused: I team iniziano a riconoscere l’esistenza dei rischi, ma la gestione è ancora informale e limitata al livello di singolo team. I rischi vengono discussi durante le riunioni del team e si cerca di trovare soluzioni pragmatiche per mitigarli.
Livello 2 – Customer Driven: L’organizzazione inizia a comprendere l’importanza della gestione del rischio per la soddisfazione del cliente. Si introducono metriche per monitorare i rischi e si inizia a sviluppare una comprensione più olistica del flusso di lavoro, identificando potenziali punti deboli e colli di bottiglia.
Livello 3 – Fit for Purpose: La gestione del rischio diventa un processo più formale e integrato nel sistema Kanban. Si utilizzano le classi di servizio per dare priorità al lavoro in base al rischio e al valore per il cliente. Si implementano meccanismi di feedback per apprendere dagli errori e migliorare continuamente la gestione del rischio.
Livello 4 – Risk Hedged: L’organizzazione sviluppa una solida capacità di gestione del rischio. Si implementano processi di governance del rischio e si utilizzano metriche avanzate per monitorare le prestazioni e identificare le aree di miglioramento.
Livello 5 – Market Leader: La gestione del rischio diventa parte integrante della cultura organizzativa. L’organizzazione è in grado di anticipare i rischi e di adattarsi rapidamente ai cambiamenti del mercato. Si adotta un approccio proattivo alla gestione del rischio, investendo in innovazione e sperimentazione per mitigare i rischi futuri.
Livello 6 – Built for Survival: L’organizzazione è in grado di gestire eventi imprevisti e di alta criticità. Si sviluppano piani di emergenza e si mettono in atto strategie per garantire la resilienza e la continuità operativa, anche in scenari di crisi. Un’organizzazione a questo livello di maturità è antifragile, sa trarre beneficio dagli shock estremi (i ‘Cigni neri’) e sfruttarli a proprio favore per crescere.
In sintesi, la gestione del rischio nel KMM evolve da un approccio reattivo e informale a un processo proattivo, integrato e strategico. La maturità della leadership gioca un ruolo fondamentale in questo processo, guidando l’organizzazione verso una maggiore consapevolezza e una gestione più efficace del rischio.
Conclusione
La comprensione dei concetti di Extremistan e Mediocristan, la loro relazione con i rischi di variazione, l’evoluzione della maturità organizzativa sono fattori cruciali per una gestione del rischio efficace in un sistema Kanban. Analizzando la distribuzione dei Lead Time e implementando opportune strategie di gestione e controllo del flusso di lavoro, è possibile mitigare i rischi e migliorare la prevedibilità delle prestazioni dei servizi, anche in contesti complessi e incerti.
Qualche giorno fa, un team IT con cui collaboro da tempo, e che ha già sviluppato un sistema Kanban abbastanza sofisticato, stava facendo un’analisi più puntuale del flusso di lavorazione dei ticket del proprio service desk e delle performance rispetto agli SLA (accordi sul livello di servizio).
Analizzando le metriche il team ha notato che a volte il servizio viene erogato (dalla prima risposta alla risoluzione) in tempi superiori a quelli previsti dagli SLA e si è accorto che questo succede in un caso specifico.
Viene aperto un ticket al quale viene assegnata priorità bassa o media. Il fornitore ci mette molto a rispondere e con il passare del tempo la priorità si alza. A un certo punto il ticket diventa a priorità alta, quando però è troppo tardi per risolverlo nel rispetto dei tempi previsti dagli SLA per la priorità alta (più stringenti rispetto a quelli per i ticket a priorità più bassa).
L’esempio che mi è stato fatto è quello di un incidente su un software di gestione ordini. Era stato aperto con priorità media. Dopo due settimane l’utente doveva procedere con gli ordini altrimenti l’azienda sarebbe restata senza materiali e la priorità era stata cambiata in alta. Assegnando una priorità più alta al ticket (con uno SLA più stringente), il team si è ritrovato immediatamente fuori SLA.
Questa è la tipica situazione in cui il team, nel proprio percorso di maturazione, si rende conto di avere bisogno di qualcosa di nuovo per gestire sempre meglio il proprio flusso di lavoro. E lo chiede al Kanban coach.
Da una gestione reattiva a una gestione proattiva delle dipendenze e del rischio correlato
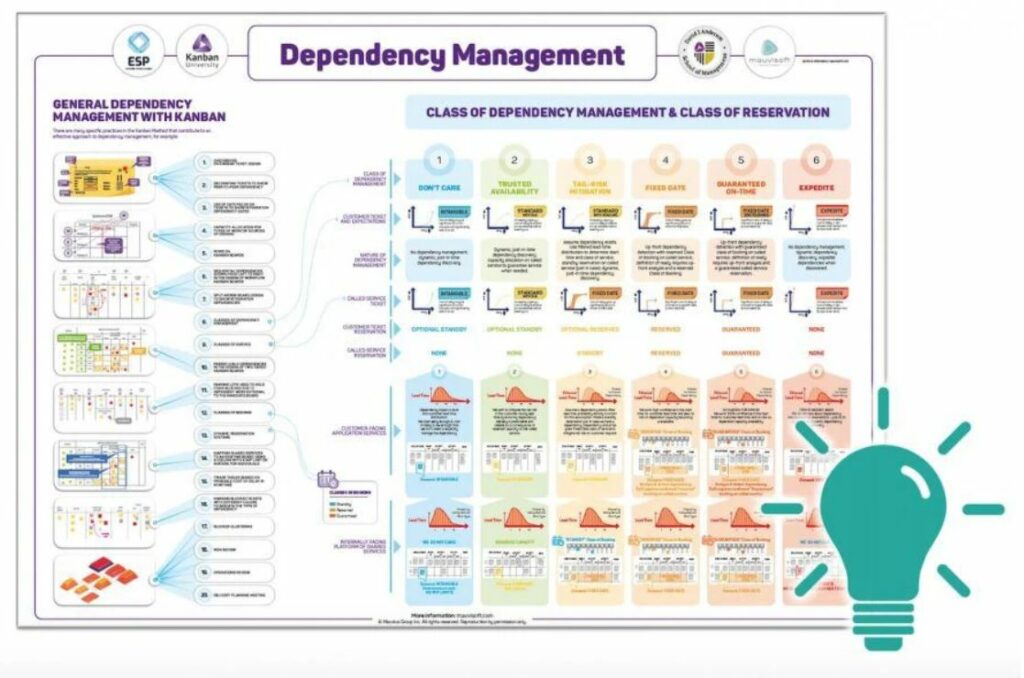
Ho fatto riflettere il team sul fatto che la gestione delle dipendenze (dai fornitori, ma non solo) fatta fin lì era stata reattiva, mentre era arrivato il momento di introdurre le cosiddette ‘classi di dipendenza’ (Classes of Dependency Management), ovvero fare il triage anche a valle sui fornitori e, in funzione di quello, agire in modo proattivo, anticipando i problemi.
Dobbiamo considerare il flusso di lavoro su cui stiamo lavorando, nel nostro esempio il nostro service desk, come un servizio che chiama un altro servizio, nel nostro esempio il servizio di assistenza del fornitore.
In un sistema Kanban possiamo disporre di metriche di flusso, tra cui una curva di distribuzione dei Lead Time relativa allo step del flusso di lavoro in cui siamo in attesa del fornitore. La stessa curva rappresenta una buona approssimazione del Lead Time del nostro fornitore e possiamo utilizzarla per calcolare il livello di rischio che abbiamo rispetto al fatto che il fornitore ritardi la risoluzione del ticket. Disporre della metrica relativa al fornitore significa che possiamo valutare quanto questo sia affidabile e capire cosa aspettarci, in modo da poterci regolare di conseguenza.
Gestire le priorità in funzione delle classi di dipendenza
Possiamo quindi, in funzione del rischio calcolato sul tempo di risposta del fornitore, assegnare la classe di dipendenza e agire come segue:
aprire il ticket al fornitore con una priorità più alta rispetto a quella che esponiamo a monte all’utente del nostro servizio
eventualmente alzare da subito la priorità anche del nostro servizio
in funzione della classe di dipendenza attribuita e se esiste un buon livello di collaborazione, si può chiedere proattivamente al fornitore di riservare della capacità produttiva, in modo puntuale e dinamico
eventualmente si può riservare della capacità produttiva anche nel nostro servizio, per accelerare le nostre operazioni quando finalmente il fornitore risponde
Da un punto di vista pratico e in termini di visualizzazione, si contrassegna il ticket con un’etichetta che corrisponde alla classe di dipendenza. Si stabilisce quindi una policy correlata alla classe di dipendenza in base alla quale l’elemento di lavoro viene trattato opportunamente.
Conclusione
Sostanzialmente il rischio correlato alla dipendenza dal fornitore viene gestito giocando d’anticipo, in modo proattivo, sistematico e standardizzato. In questo modo non viene più cambiata la priorità in corso di lavorazione ai ticket perché, a fronte di un rischio, la policy che regola la gestione della classe di dipendenza prevede già una priorità più alta e le opportune contromisure. E anche a fronte di un fornitore poco affidabile, il nostro flusso di lavoro risulta maggiormente prevedibile e affidabile, aumentando la soddisfazione degli utilizzatori del nostro servizio.
C’è molta confusione in circolazione sul concetto di “agilità”, in questo articolo voglio spiegare come la vera agilità aziendale e organizzativa sia la scienza di posticipare le decisioni, ma non troppo. Una scienza, non un’arte, perché alla base c’è il metodo scientifico.
Cos’è l’agilità aziendale e qual è il suo impatto operativo
L’agilità aziendale è la capacità di un’organizzazione di rispondere rapidamente ai cambiamenti, lasciando al proprio cliente la possibilità di cambiare in corso d’opera i requisiti del lavoro richiesto, in qualunque momento. Questo per ottenere un risultato finale che sia il più aderente possibile ai desiderata del cliente stesso.
Da un punto di vista operativo, di chi deve fare il lavoro, l’agilità si riflette nella convenienza di aspettare il più possibile a decidere e a impegnarsi a fare il lavoro. Questo approccio aumenta le opzioni disponibili e la possibilità di cambiare i requisiti del lavoro da fare, senza però essersi ancora impegnati a farlo e quindi senza sostenere eventuali costi di rilavorazione.
Sapere quanto aspettare prima di iniziare il lavoro
L’attesa d’altro canto aumenta anche la probabilità di consegnare il lavoro in ritardo. E quindi diventa cruciale sapere quanto si può aspettare prima di iniziare il lavoro e diventa fondamentale il ruolo delle metriche di flusso. E per poter disporre di metriche di flusso affidabili occorre un sistema stabile e prevedibile, che possiamo ottenere attraverso l’implementazione di un sistema Kanban.
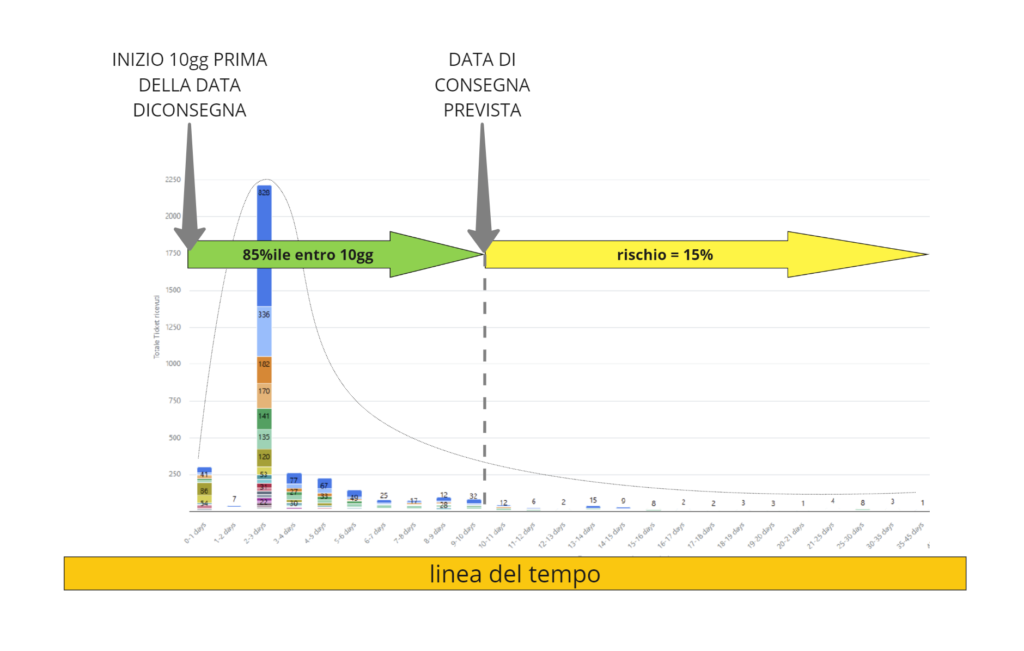
Considerando per i servizi, come in figura, il tipico valore dell’ottantacinquesimo percentile (ma può variare in funzione della criticità del servizio stesso), si dovrà iniziare il lavoro con un anticipo rispetto alla data di consegna prevista che dia una confidenza statistica almeno dell’85% o, se preferiamo, un rischio massimo del 15% di ritardare rispetto alla data promessa, circa una volta su sette.
Pianificare utilizzando il Lead Time
La pianificazione e il successivo controllo di qualunque attività aziendale, sia delle attività correnti che delle attività relative ai progetti, viene fatta di conseguenza basandosi sui valori di Lead Time e diventa più accurata e affidabile, oltre che meno costosa da gestire. Invece di concentrarsi sulla stima dell’effort e l’aggiunta di fattori di rischio, Kanban si basa sui dati empirici del flusso di lavoro per prevedere in modo probabilistico le date di consegna.
Il metodo Kanban offre quindi un approccio alla pianificazione significativamente più vantaggioso rispetto ai metodi tradizionali. In definitiva, l’approccio di pianificazione basato sul Lead Time di Kanban promuove l’agilità aziendale, la consegna puntuale e la soddisfazione del cliente. A costi più bassi.
Uno degli aspetti che comunemente non sono così noti e chiari è il fatto che il metodo Kanban aiuta a ridurre il rischio operativo e gli errori previsionali. La difficoltà iniziale delle persone alle quali ne parlo parte proprio dalla comprensione del concetto di rischio operativo. “Quale rischio operativo?” mi chiedono. “Il rischio legato al fatto che a causa di diversi eventi, interni o esterni all’organizzazione, potremmo metterci più di quanto previsto per fare il lavoro” rispondo. “In che senso?” insistono. Allora comincio a porre loro alcune domande.
Il concetto di Lead Time
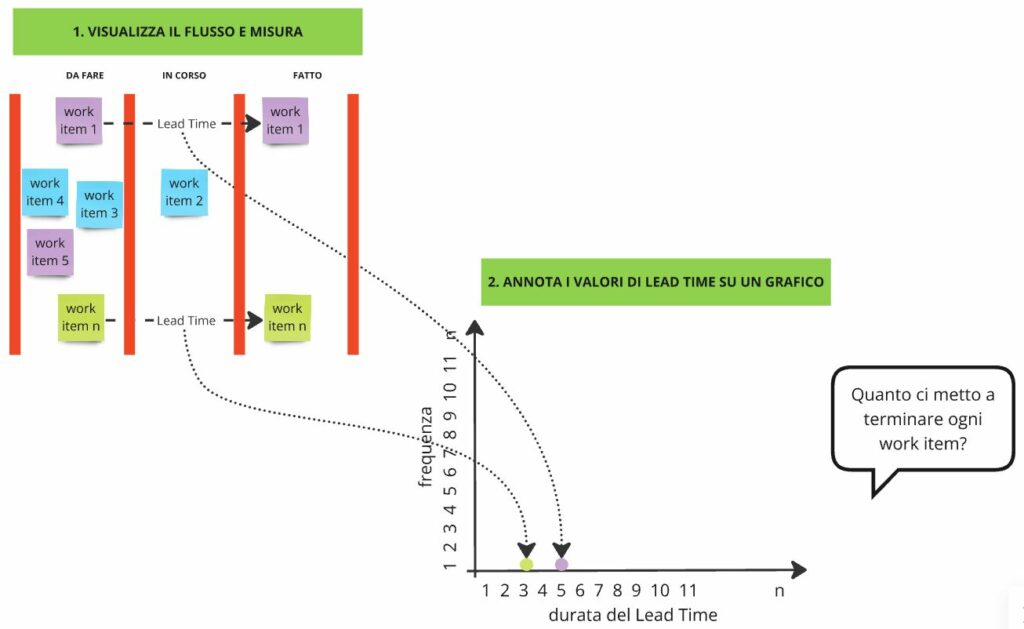
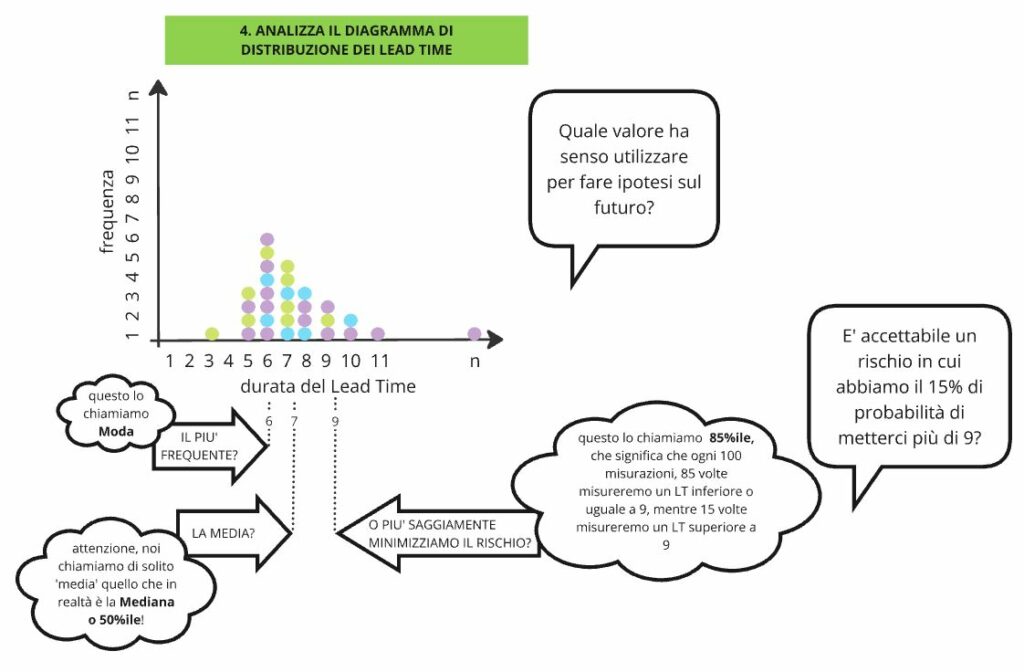
Chiedo di farmi un esempio di qualche tipica richiesta di lavoro che ricevono. “Quanto tempo ci mettete per evadere questa richiesta di lavoro?” chiedo. La risposta tipicamente è un numero. “Siamo sicuri?” chiedo. “Come varia questo valore a seconda delle circostanze, lo sapete?”. Normalmente la risposta è vaga.
Allora comincio a disegnare su un foglio o su una lavagna una rappresentazione di una semplice Kanban board come in Figura 1. Spiego che chiameremo Lead Time il tempo che ogni richiesta di lavoro (che chiameremo Work Item) ci mette per essere evasa e spiego che il Lead Time non è un unico valore ma una distribuzione di valori. Poi ripeto la domanda: “Quanto tempo ci mettete per evadere questa richiesta di lavoro?” e quindi, senza aspettare la risposta, spiego che il tempo rilevato di evasione della richiesta può variare e comincio ad annotare i valori su un grafico come in Figura 1.
Figura 1
La distribuzione dei Lead Time
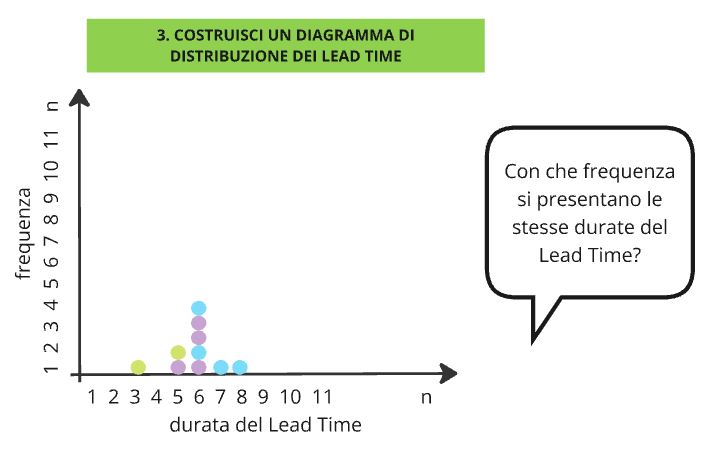
Proseguendo ad aggiungere valori chiedo: “succede che i valori di Lead Time si ripetano, giusto?” e così facendo vado ad aggiungere al grafico i valori che si ripetono impilandoli ai precedenti, fino a raggiungere una rappresentazione come in Figura 2. A questo punto verifico con i miei interlocutori se si ritrovano nel grafico disegnato, normalmente rispondono di sì.
Figura 2
Quale valore utilizzare per fare previsioni
Siamo pronti allora per il passo successivo che consiste nell’invitare i miei interlocutori a rispondere alla domanda: “quale dei valori misurati secondo voi ha senso utilizzare per fare previsioni future?” e qui inizia la vera riflessione, come in Figura 3.
Figura 3
Qualcuno risponde “la media” e allora faccio riflettere sul fatto che solitamente si dice ‘media’ riferendosi a quel valore per cui una volta su due ci si mette di più, mentre una volta su due ci si mette di meno del valore stesso. Questo in termini statistici però non è il concetto di media, ma più propriamente è quello di mediana, anche nota come cinquantesimo percentile. Quindi faccio notare come prendendo a riferimento la mediana saremo in ritardo una volta su due, ossia avremo il 50% di probabilità di non essere puntuali, che è un rischio piuttosto elevato, probabilmente non accettabile.
Qualcuno allora mi risponde “il valore più frequente”. Faccio notare che il valore più frequente, in termini statistici detto moda, nel grafico è tipicamente più a sinistra della mediana, il che significa che ho ancora più probabilità di essere in ritardo rispetto ad utilizzare la mediana, corro un rischio ancora più elevato, superiore al 50%.
Parliamo di rischio operativo
Arrivati a questo punto cambio prospettiva alla riflessione e chiedo “guardiamola dal punto di vista del rischio, quale probabilità di arrivare in ritardo siete disposti ad accettare? O meglio, quale probabilità di arrivare in ritardo sono disposti ad accettare i clienti del vostro servizio?” Qui le risposte sono ovviamente molto diverse a seconda dei servizi e dei casi, ma di base propongo loro di ragionare intorno all’ottantacinquesimo percentile, ovvero il valore previsionale in base al quale ci si prende un rischio del 15% di arrivare in ritardo, che normalmente per i servizi è accettato e che si usa in Kanban.
Per concludere faccio infine notare come fare previsioni sul completamento di una richiesta di lavoro senza misurare i Lead Time e senza effettuare un’analisi statistica sia fuorviante perché essendo noi tutti soggetti ai bias cognitivi e in particolare all’euristica della disponibilità, tenderemo automaticamente ad adottare il valore più frequente, prendendoci dei rischi inaccettabili senza nemmeno rendercene conto.
Conclusione
Chiaramente questo è solo l’inizio e ci sono altri passaggi da fare per introdurre efficacemente gli strumenti statistici, a cominciare dalla comprensione del tipo di curva di distribuzione presente e dalla validazione del modello che emerge dalla rilevazione dei dati. Normalmente però queste riflessioni avviano un percorso evolutivo che porta progressivamente nel tempo a un miglioramento sostanziale dei modelli previsionali, alla stabilizzazione dei flussi di lavoro e quindi a una migliore gestione del servizio.